Usualmente, arquivos GTFS provenientes de fontes oficiais são utilizados para desenvolver análises e pesquisas que possuem diversos elementos comuns. Visando facilitar a leitura, o processamento e a análise desses dados, a equipe do Projeto Acesso a Oportunidades vem desenvolvendo o pacote de R {gtfstools}, que disponibiliza diversas funções que facilitam a manipulação e a exploração de feeds.
Neste capítulo, passaremos por algumas das funcionalidades mais frequentemente utilizadas do pacote. Para isso, vamos utilizar uma amostra do feed da SPTrans apresentado no capítulo anterior, disponível dentro do {gtfstools}.
5.1 Leitura e manipulação básica de arquivos GTFS
A leitura de arquivos GTFS com o {gtfstools} é feita com a função read_gtfs(), que recebe uma string com o caminho do arquivo. Após sua leitura, o feed é representado como uma lista de data.tables, uma versão de alta performance da classe data.frame. Ao longo deste capítulo, vamos nos referir a essa lista de tabelas como um objeto GTFS. Por padrão, a função lê todas as tabelas .txt do feed:
# carrega bibliotecalibrary(gtfstools)# aponta para o endereço do arquivo gtfs dentro do {gtfstools}endereco <-system.file("extdata/spo_gtfs.zip", package ="gtfstools")# le o gtfsgtfs <-read_gtfs(endereco)# consulta o nome das tabelas dentro da listanames(gtfs)
Como podemos ver, cada data.table dentro do objeto GTFS é nomeado de acordo com a tabela que ele representa, sem a extensão .txt. Isso nos permite selecionar e manipular cada uma das tabelas separadamente. O código adiante, por exemplo, mostra os seis primeiros registros da tabela trips:
As tabelas dentro de um objeto GTFS podem ser facilmente manipuladas usando a sintaxe dos pacotes {dplyr} ou {data.table}. Neste livro, optamos por utilizar a sintaxe do {data.table}, pois esse pacote oferece diversas funcionalidades úteis para a manipulação de tabelas com grande quantidade de registros, tal como a edição de colunas por referência, filtros de linhas muito rápidos e agregação de dados eficiente1. Para adicionar cem segundos a todos os headways listados na tabela frequencies e reverter essa mudança em seguida, por exemplo, podemos usar o código a seguir:
# salva o headway originalheadway_original <- gtfs$frequencies$headway_secshead(gtfs$frequencies, 3)
Após editarmos um objeto GTFS no R, frequentemente vamos querer utilizá-lo para fazer análises de diferentes tipos. Para isso, é comum que precisemos do arquivo GTFS em formato .zip novamente, e não como uma lista de tabelas dentro do R. O pacote {gtfstools} disponibiliza a função write_gtfs() exatamente com a finalidade de transformar objetos GTFS que existem apenas dentro do R em arquivos GTFS armazenados no seu computador. Para usarmos essa função, precisamos apenas listar o objeto e o endereço no qual o arquivo deve ser salvo:
# aponta para o endereço onde arquivo deve ser salvoendereco_destino <-tempfile("novo_gtfs", fileext =".zip")# salva o GTFS no enderecowrite_gtfs(gtfs, path = endereco_destino)# lista arquivos dentro do feed recém-salvozip::zip_list(endereco_destino)[, c("filename", "compressed_size", "timestamp")]
Arquivos GTFS são frequentemente utilizados em estimativas de roteamento de transporte público e para informar passageiros sobre a tabela de horários das diferentes rotas que operam em uma região. Dessa forma, é extremamente importante que o cronograma das viagens e a velocidade operacional de cada linha estejam adequadamente descritos no feed.
O {gtfstools} disponibiliza a função get_trip_speed() para facilitar o cálculo da velocidade de cada viagem presente no feed. Por padrão, a função calcula a velocidade (em km/h) de todas as viagens do GTFS, mas viagens individuais também podem ser especificadas:
# calcula a velocidade de todas as viagensvelocidades <-get_trip_speed(gtfs)head(velocidades)
Calcular a velocidade de uma viagem requer que saibamos o seu comprimento e em quanto tempo ela foi realizada. Para isso, a get_trip_speed() utiliza duas outras funções do {gtfstools} por trás dos panos: a get_trip_length() e a get_trip_duration(). O funcionamento das duas é muito parecido com o mostrado anteriormente, calculando o comprimento/duração de todas as viagens por padrão, ou de apenas algumas selecionadas, caso desejado. A seguir, mostramos seus comportamentos padrões.
# calcula a distância percorrida de todas viagensdistancias <-get_trip_length(gtfs, file ="shapes")head(distancias)
Assim como a get_trip_speed() calcula as velocidades em km/h por padrão, a get_trip_length() e a get_trip_duration() calculam os comprimentos e as durações em quilômetros e em minutos, respectivamente. Essas unidades podem ser ajustadas com o argumento unit, presente nas três funções.
5.3 Combinando e filtrando feeds
Muitas vezes, o processamento e a edição de arquivos GTFS são realizados, em grande medida, manualmente. Por isso, pequenas inconsistências podem passar batidas pelos responsáveis por esse processamento. Um problema comumente observado em feeds é a presença de registros duplicados em uma mesma tabela. O feed da SPTrans, por exemplo, possui registros duplicados tanto no agency.txt quanto no calendar.txt:
O {gtfstools} disponibiliza a função remove_duplicates() para remover essas duplicatas. Essa função recebe como input um objeto GTFS e retorna o mesmo objeto, porém sem registros duplicados:
Frequentemente, também, lidamos com múltiplos feeds em uma mesma área de estudo. Por exemplo, quando os dados dos sistemas de ônibus e de trens de uma mesma cidade estão salvos em arquivos GTFS separados. Nesse caso, muitas vezes gostaríamos de uni-los em um único arquivo, diminuindo assim o esforço de manipulação e processamento dos dados. Para isso, o {gtfstools} disponibiliza a função merge_gtfs(). O exemplo a seguir mostra o resultado da combinação de dois feeds distintos, o da SPTrans (sem duplicatas) e o da EPTC, de Porto Alegre:
# lê GTFS de Porto Alegreendereco_poa <-system.file("extdata/poa_gtfs.zip", package ="gtfstools")gtfs_poa <-read_gtfs(endereco_poa)gtfs_poa$agency
agency_id agency_name agency_url
1: EPTC Empresa Publica de Transportes e Circulação http://www.eptc.com.br
agency_timezone agency_lang agency_phone
1: America/Sao_Paulo pt 156
agency_fare_url
1: http://www2.portoalegre.rs.gov.br/eptc/default.php?p_secao=155
# combina objetos GTFS de Porto Alegre e São Paulogtfs_combinado <-merge_gtfs(gtfs_sem_dups, gtfs_poa)# checa resultadosgtfs_combinado$agency
agency_id agency_name
1: 1 SPTRANS
2: EPTC Empresa Publica de Transportes e Circulação
agency_url agency_timezone agency_lang
1: http://www.sptrans.com.br/?versao=011019 America/Sao_Paulo pt
2: http://www.eptc.com.br America/Sao_Paulo pt
agency_phone agency_fare_url
1:
2: 156 http://www2.portoalegre.rs.gov.br/eptc/default.php?p_secao=155
Como podemos ver, os registros das tabelas de ambos os feeds foram combinados em uma única tabela. Esse é o caso quando os dois (ou mais, se desejado) objetos GTFS possuem registros de uma mesma tabela (a agency, no exemplo). Caso apenas um dos objetos possua uma das tabelas, a operação copia essa tabela para o resultado final. É o caso, por exemplo, da tabela frequencies, que existe no feed da SPTrans, mas não no da EPTC:
Um outro tipo de operação muito utilizada no tratamento de dados GTFS é o de filtragem desses arquivos. Frequentemente, feeds são usados para descrever redes de transporte público de grande escala, o que pode transformar sua edição, sua análise e seu compartilhamento em operações complexas. Por esse motivo, pesquisadores e planejadores muitas vezes precisam trabalhar com um subconjunto de dados descritos nos feeds. Por exemplo, caso desejemos estimar a performance da rede de transporte em uma determinada região no horário de pico da manhã, podemos filtrar o nosso arquivo GTFS de modo a manter apenas os registros referentes a viagens que ocorrem nesse intervalo do dia.
O pacote {gtfstools} traz diversas funções para facilitar a filtragem de arquivos GTFS. São elas:
filter_by_agency_id();
filter_by_route_id();
filter_by_service_id();
filter_by_shape_id();
filter_by_stop_id();
filter_by_trip_id();
filter_by_route_type();
filter_by_weekday();
filter_by_time_of_day(); e
filter_by_sf().
5.3.1 Filtro por identificadores
As sete primeiras funções mencionadas anteriormente são utilizadas de forma muito similar. Devemos especificar um vetor de identificadores que é usado para manter no objeto GTFS apenas os registros relacionados a esses identificadores. O exemplo a seguir demonstra essa funcionalidade com a filter_by_trip_id():
# checa tamanho do feed antes do filtroutils::object.size(gtfs)
# mantém apenas registros relacionados a duas viagensgtfs_filtrado <-filter_by_trip_id( gtfs,trip_id =c("CPTM L07-0", "CPTM L07-1"))# checa tamanho do feed após o filtroutils::object.size(gtfs_filtrado)
O código mostra que a função não filtra apenas a tabela trips, mas também as outras tabelas que possuem algum tipo de relação com os identificadores especificados. Por exemplo, a trajetória das viagens CPTM L07-0 e CPTM L07-1 é descrita pelos shape_ids 17846 e 17847, respectivamente. Esses são, portanto, os únicos identificadores da tabela shapes mantidos no GTFS filtrado.
A função também pode funcionar com o comportamento diametralmente oposto: em vez de definirmos os identificadores cujos registros devem ser mantidos no feed, podemos especificar os identificadores que devem ser retirados dele. Para isso, usamos o argumento keep com valor FALSE:
# remove duas viagens do feedgtfs_filtrado <-filter_by_trip_id( gtfs,trip_id =c("CPTM L07-0", "CPTM L07-1"),keep =FALSE)head(gtfs_filtrado$trips[, .(trip_id, trip_headsign, shape_id)])
trip_id trip_headsign shape_id
1: CPTM L08-0 AMADOR BUENO 17848
2: CPTM L08-1 JULIO PRESTES 17849
3: CPTM L09-0 GRAJAU 17850
4: CPTM L09-1 OSASCO 17851
5: CPTM L10-0 RIO GRANDE DA SERRA 17852
6: CPTM L10-1 BRÁS 17853
Como podemos ver, as viagens especificadas, bem como suas trajetórias, não estão presentes no GTFS filtrado. A mesma lógica aqui demonstrada com a filter_by_trip_id() é válida para as funções que filtram objetos GTFS pelos identificadores agency_id, route_id, service_id, shape_id, stop_id e route_type.
5.3.2 Filtro por dia e hora
Outra operação que recorrentemente aparece em análises que envolvem dados GTFS é a de manter serviços que funcionem apenas em determinados horários do dia ou dias da semana. Para isso, o pacote disponibiliza as funções filter_by_weekday() e filter_by_time_of_day().
A filter_by_weekday() recebe os dias da semana (em inglês) cujos serviços que neles operam devem ser mantidos. Adicionalmente, a função também inclui o argumento combine, que define como filtros de dois ou mais dias funcionam. Quando este recebe o valor ”and”, apenas serviços que operam em todos os dias especificados são mantidos. Quando recebe o valor ”or”, serviços que operam em pelo menos um dos dias são mantidos:
# mantém apenas serviços que operam no sábado E no domingogtfs_filtrado <-filter_by_weekday(gtfs = gtfs_sem_dups,weekday =c("saturday", "sunday"),combine ="and")gtfs_filtrado$calendar[, c("service_id", "sunday", "saturday")]
service_id sunday saturday
1: USD 1 1
2: _SD 1 1
# mantém apenas serviços que operam OU no sábado OU no domingogtfs_filtrado <-filter_by_weekday(gtfs = gtfs_sem_dups,weekday =c("sunday", "saturday"),combine ="or")gtfs_filtrado$calendar[, c("service_id", "sunday", "saturday")]
A filter_by_time_of_day(), por sua vez, recebe o começo e o final de uma janela de tempo e mantém os registros relacionados a viagens que rodam dentro dessa janela. O funcionamento da função depende da presença ou não da tabela frequencies no objeto GTFS: o cronograma descrito na stop_times das viagens listadas na tabela frequencies não deve ser filtrado, pois, como comentado no capítulo anterior, ele serve como um modelo que dita o tempo de viagem entre uma parada e outra. Caso a frequencies esteja ausente, no entanto, a stop_times é filtrada segundo o intervalo de tempo especificado. Vamos ver como isso funciona com um exemplo:
# mantém apenas viagens dentro do período de 5 às 6 da manhãgtfs_filtrado <-filter_by_time_of_day(gtfs, from ="05:00:00", to ="06:00:00")head(gtfs_filtrado$frequencies)
# salva a tabela frequencies e a remove do objeto gtfsfrequencies <- gtfs$frequenciesgtfs$frequencies <-NULLgtfs_filtrado <-filter_by_time_of_day(gtfs, from ="05:00:00", to ="06:00:00")head(gtfs_filtrado$stop_times[, c("trip_id", "departure_time", "arrival_time")])
O filtro da tabela stop_times pode funcionar de duas formas distintas: mantendo intactas todas as viagens que cruzam a janela de tempo especificada; ou mantendo no cronograma apenas as paradas que são visitadas dentro da janela (comportamento padrão da função). Esse comportamento é controlado com o parâmetro full_trips, como mostrado a seguir (atenção aos horários e aos segmentos presentes em cada exemplo):
# mantém apenas viagens inteiramente dentro do período de 5 às 6 da manhãgtfs_filtrado <-filter_by_time_of_day( gtfs,from ="05:00:00", to ="06:00:00",full_trips =TRUE)head( gtfs_filtrado$stop_times[ ,c("trip_id", "departure_time", "arrival_time", "stop_sequence") ])
# mantém apenas paradas que são visitadas entre 5 e 6 da manhãgtfs_filtrado <-filter_by_time_of_day( gtfs,from ="05:00:00",to ="06:00:00",full_trips =FALSE)head( gtfs_filtrado $stop_times[ ,c("trip_id", "departure_time", "arrival_time", "stop_sequence") ])
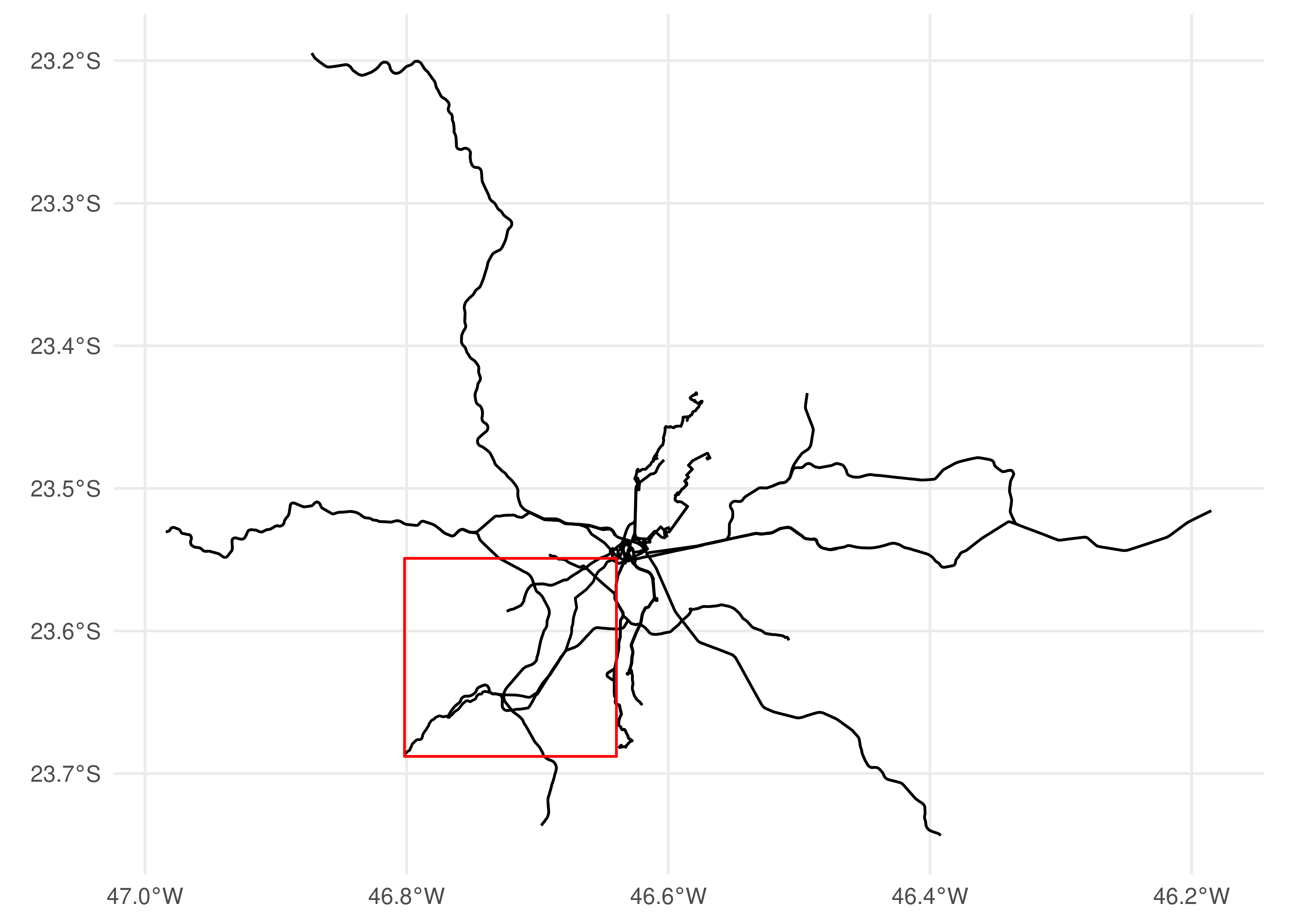
Por fim, o {gtfstools} também disponibiliza uma função que permite filtrar o objeto GTFS usando um polígono espacial. A filter_by_sf() recebe um objeto do tipo sf/sfc (representação espacial criada pelo pacote {sf}), ou sua bounding box, e mantém os registros cujas viagens são selecionadas por uma operação espacial que também deve ser especificada. Embora aparentemente complicado, esse processo de filtragem é compreendido com facilidade quando apresentado visualmente. Para isso, vamos filtrar o GTFS da SPTrans pela bounding box da trajetória 68962. Com o código a seguir, apresentamos a distribuição espacial dos dados não filtrados, com a bounding box destacada em vermelho na Figura 5.1.
# carrega biblioteca ggplot2 para visualização de dadoslibrary(ggplot2)# cria poligono com a bounding box da trajetoria 68962trajetoria_68962 <-convert_shapes_to_sf(gtfs, shape_id ="68962")bbox <- sf::st_bbox(trajetoria_68962)geometria_bbox <- sf::st_as_sfc(bbox)# gera geometria de todas as trajetorias do gtfstodas_as_trajetorias <-convert_shapes_to_sf(gtfs)ggplot() +geom_sf(data = todas_as_trajetorias) +geom_sf(data = geometria_bbox, fill =NA, color ="red") +theme_minimal()
Figura 5.1: Distribuição espacial das trajetórias, com a bounding box da trajetória 68962 em destaque
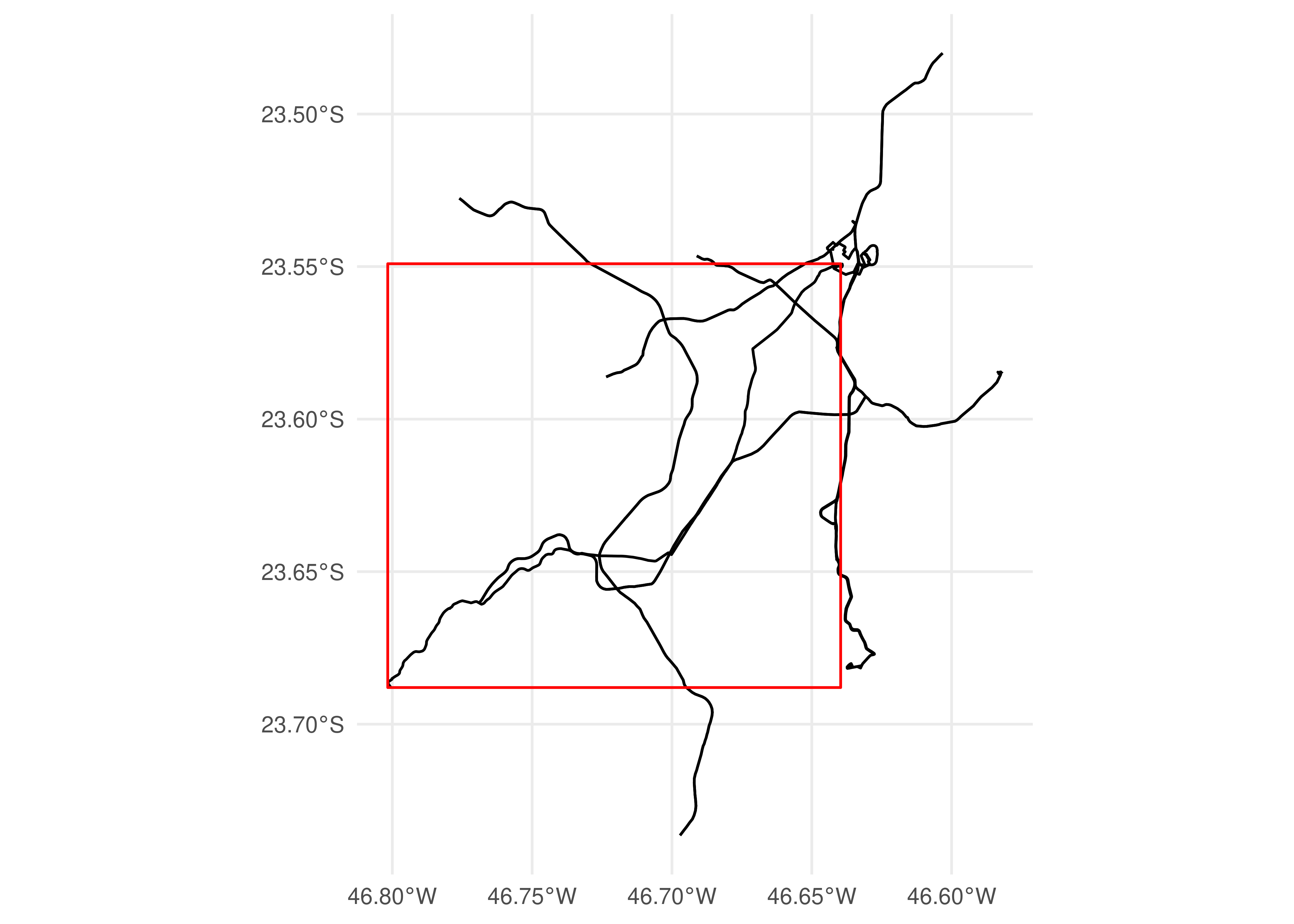
Note que usamos a função convert_shapes_to_sf(), também disponibilizada pelo {gtfstools}, que converte uma determinada trajetória descrita no GTFS em um objeto espacial do tipo sf. Por padrão, a filter_by_sf() mantém os dados relacionados aos registros de viagens cujas trajetórias possuem alguma interseção com o polígono espacial selecionado:
gtfs_filtrado <-filter_by_sf(gtfs, bbox)trajetorias_filtradas <-convert_shapes_to_sf(gtfs_filtrado)ggplot() +geom_sf(data = trajetorias_filtradas) +geom_sf(data = geometria_bbox, fill =NA, color ="red") +theme_minimal()
Figura 5.2: Distribuição espacial das trajetórias com interseções com a bounding box da trajetória 68962
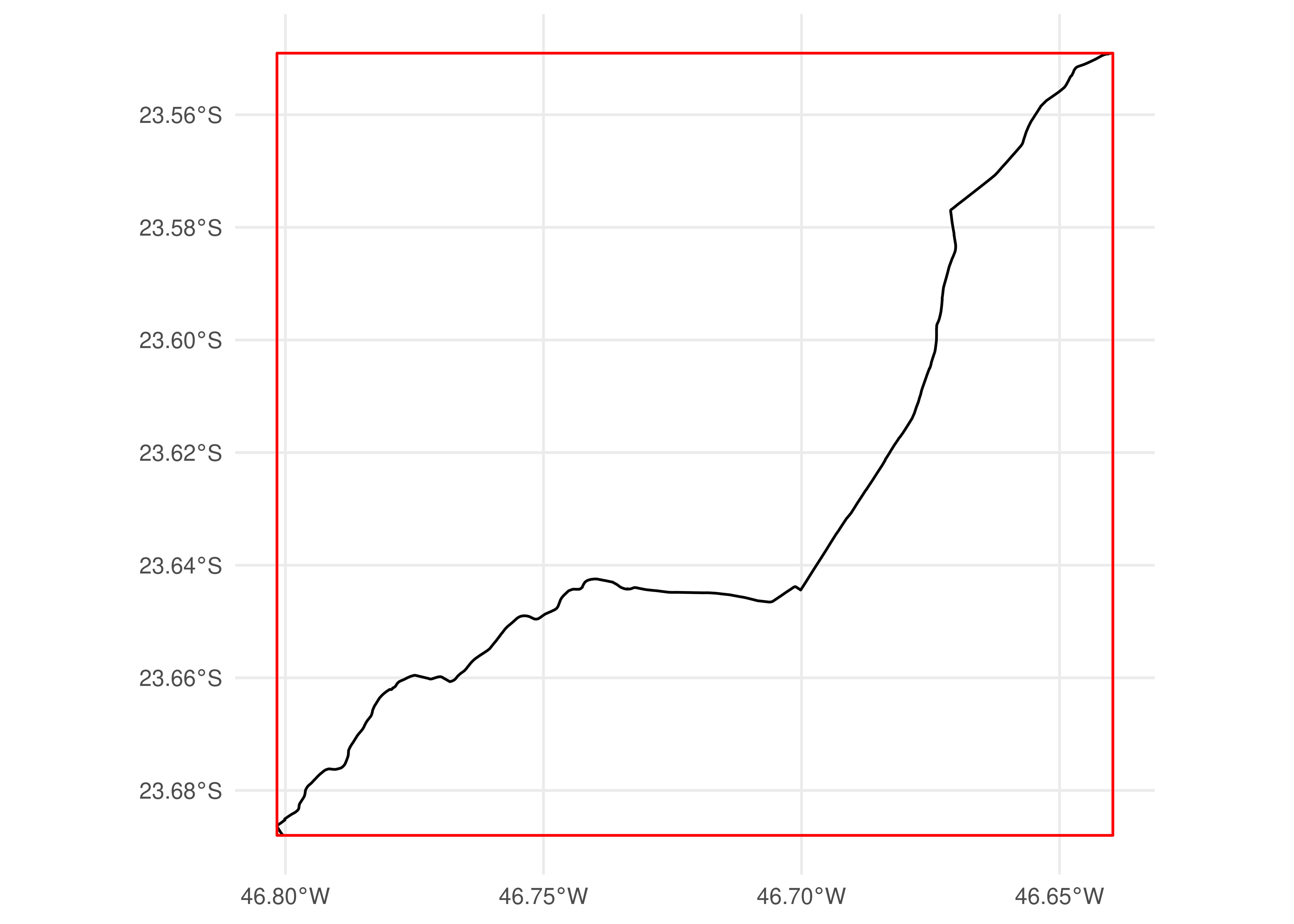
Podemos, no entanto, controlar a operação espacial usada no processo de filtragem. Por exemplo, o código adiante mostra como podemos manter os dados relacionados a viagens que estão contidas dentro do polígono espacial:
gtfs_filtrado <-filter_by_sf(gtfs, bbox, spatial_operation = sf::st_contains)trajetorias_filtradas <-convert_shapes_to_sf(gtfs_filtrado)ggplot() +geom_sf(data = trajetorias_filtradas) +geom_sf(data = geometria_bbox, fill =NA, color ="red") +theme_minimal()
Figura 5.3: Distribuição espacial das trajetórias contidas na bounding box da trajetória 68962
5.4 Validação de arquivos GTFS
Planejadores e pesquisadores frequentemente querem avaliar a qualidade dos arquivos GTFS que estão utilizando em suas análises ou que estão produzindo. Os feeds estão estruturados conforme boas práticas adotadas pela comunidade que usa a especificação? As tabelas e colunas estão formatadas corretamente? A informação descrita pelo feed parece verossímil (velocidade das viagens, localização das paradas etc.)? Essas são algumas das perguntas que podem surgir ao lidar com dados no formato GTFS.
Para responder a essas e outras perguntas, o {gtfstools} inclui a função validate_gtfs(), que serve como interface entre o R e o Canonical GTFS Validator, software desenvolvido pela MobilityData. O uso do validador requer que o Java versão 11 ou superior esteja instalado2.
Usar a validate_gtfs() é muito simples. Primeiro, precisamos baixar o software de validação. Para isso, podemos usar a função download_validator(), também disponível no pacote, que recebe o endereço de uma pasta na qual o validador deve ser salvo e a versão do validador desejada (por padrão, a mais recente). Como resultado, a função retorna o endereço do arquivo baixado:
A segunda (e última) etapa consiste em de fato rodar a função validate_gtfs(). Essa função aceita que os dados GTFS a serem validados sejam passados de diferentes formas: i) como um objeto GTFS existente apenas no R; ii) como o endereço de um arquivo GTFS salvo localmente em formato .zip; iii) como uma URL apontando para um feed; ou iv) como uma pasta que contém os dados GTFS não compactados. A função também recebe o endereço para uma pasta onde o resultado da validação deve ser salvo e o endereço para o validador que deve ser usado. Nesse exemplo, vamos fazer a validação a partir do endereço do arquivo GTFS da SPTrans, lido anteriormente:
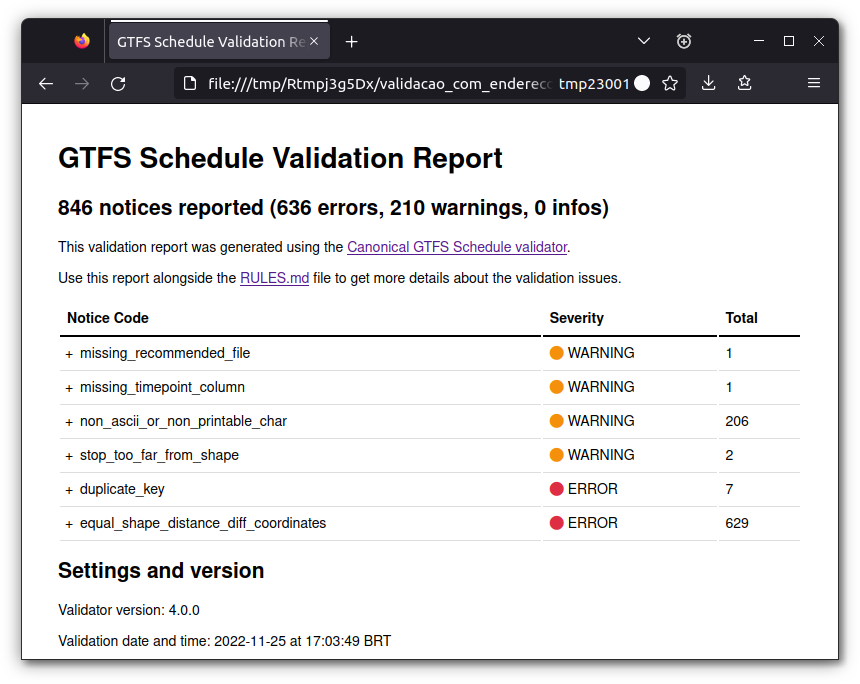
Como podemos ver, a validação gera alguns arquivos como resultado:
report.html, mostrado na Figura 5.4, que resume os resultados da validação em uma página HTML (apenas disponível quando utilizado o validador v3.1.0 ou superior);
report.json, que resume a mesma informação apresentada na página HTML, porém em formato JSON, que pode ser usado para processar e interpretar os resultados de forma programática;
system_errors.json, que apresenta eventuais erros de sistema que tenham ocorrido durante a validação e que podem comprometer os resultados; e
validation_stderr.txt, que lista mensagens informativas enviadas pelo validador, incluindo uma lista dos testes realizados, eventuais mensagens de erro etc3.
Figura 5.4: Exemplo de relatório gerado durante a validação
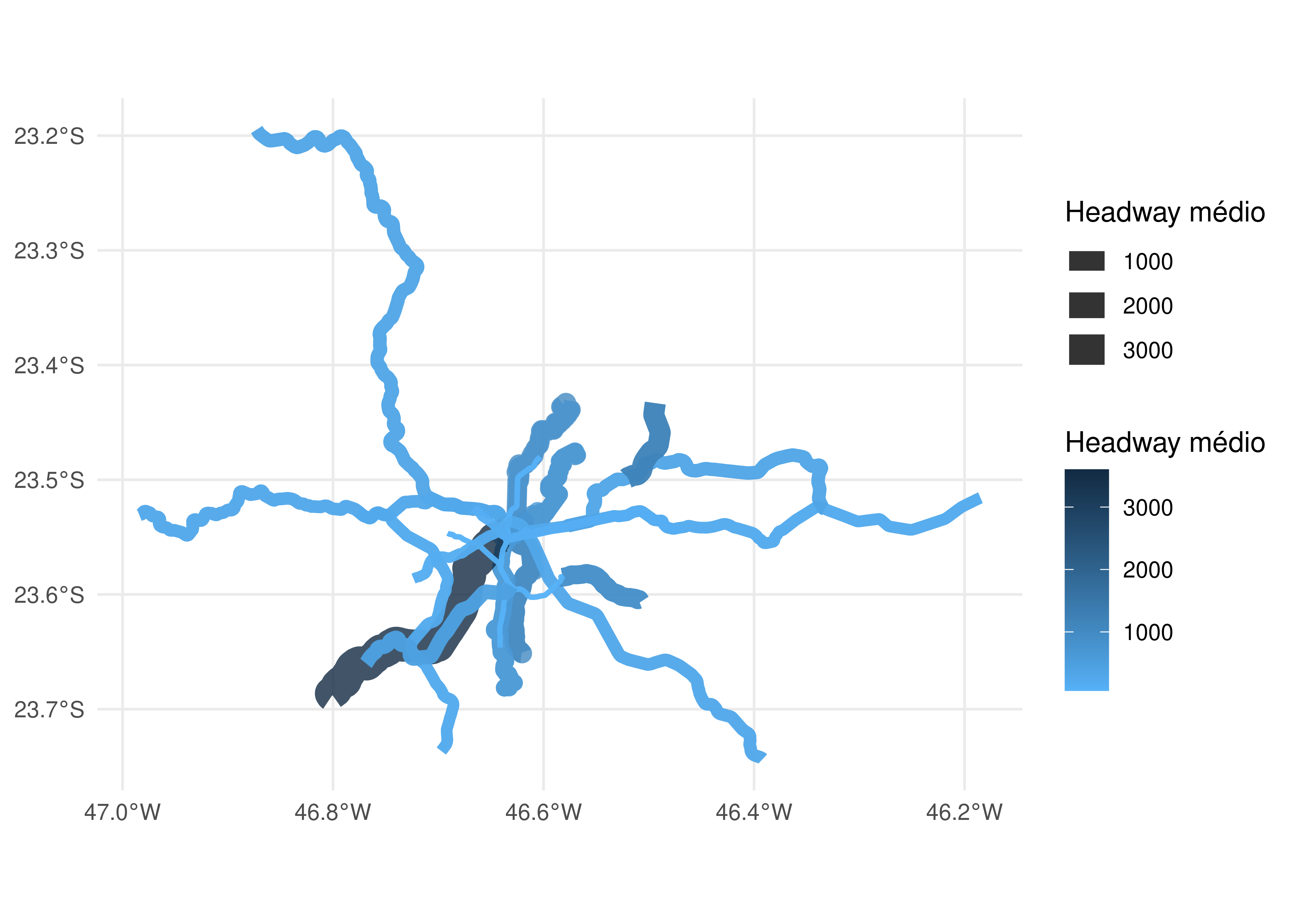
5.5 Fluxo de trabalho com o {gtfstools}: mapeando o headway das linhas
Como mostrado nas seções anteriores, o {gtfstools} disponibiliza uma grande caixa de ferramentas que podem ser usadas no processamento e na análise de arquivos GTFS. O pacote, no entanto, oferece diversas outras funções que não puderam ser apresentadas neste livro, por limitação de espaço4.
A apresentação das funções feita até aqui tem um importante caráter demonstrativo, porém não mostra como elas podem ser usadas de forma conjunta na análise de um arquivo GTFS. Esta seção preenche essa lacuna, mostrando como o pacote pode ser usado, por exemplo, para responder à seguinte pergunta: como se distribuem espacialmente os tempos entre veículos de uma mesma linha (os headways) no GTFS da SPTrans?
A primeira etapa é definir o escopo da nossa análise. Para exemplificar, vamos considerar o headway no pico da manhã, entre 7h e 9h, em uma típica terça-feira de operação. Para isso, precisamos filtrar o nosso feed:
# lê o arquivo GTFSgtfs <-read_gtfs(endereco)# filtra o GTFSgtfs_filtrado <- gtfs |>remove_duplicates() |>filter_by_weekday("tuesday") |>filter_by_time_of_day(from ="07:00:00", to ="09:00:00")# checa resultado do filtrogtfs_filtrado$frequencies[trip_id =="2105-10-0"]
Em seguida, precisamos calcular o headway dentro do período estabelecido. Essa informação pode ser encontrada na tabela frequencies, mas há um elemento complicador: cada viagem está associada a mais de um headway, como vimos anteriormente (um registro para o período entre 7h e 7h59 e outro para o período entre 8h e 8h59). Para resolver essta questão, portanto, vamos calcular o headway médio no intervalo entre 7h e 9h.
Os primeiros registros da tabela frequencies do GTFS da SPTrans parecem sugerir que os períodos do dia estão listados sempre de uma em uma hora, porém essa não é uma regra estabelecida na especificação nem é a prática adotada em outros feeds. Por isso, vamos calcular a média ponderada do headway no período especificado. Para isso, precisamos multiplicar cada headway pelo intervalo de tempo em que ele é válido e dividir o total desta soma pelo intervalo de tempo total (duas horas). Para calcular o intervalo de tempo em que cada headway é válido, calculamos o começo e o fim do intervalo em segundos com a função convert_time_to_seconds() e subtraímos o valor do fim pelo do começo, como mostrado a seguir:
Precisamos agora gerar a trajetória espacial de cada viagem e juntar essa informação à do headway médio. Para isso, vamos utilizar a função get_trip_geometry(), que, dado um objeto GTFS, gera a trajetória espacial de suas viagens. Essa função nos permite especificar as viagens cujas trajetórias queremos gerar, logo vamos calcular apenas as trajetórias daquelas que estão presentes na tabela de headways médios:
Geradas as trajetórias espaciais de cada viagem, precisamos juntá-las à informação de headway médio e, em seguida, configurar o nosso mapa como desejado. No exemplo a seguir, usamos cores e espessuras de linhas que variam de acordo com o headway de cada viagem:
Figura 5.5: Distribuição espacial dos headways no GTFS da SPTrans
Como podemos ver, o pacote {gtfstools} torna o desenvolvimento de análises de feeds de transporte público algo fácil e que requer apenas o conhecimento básico de pacotes de manipulação de tabelas (como o {data.table} e o {dplyr}). O exemplo apresentado nesta seção mostra como muitas de suas funções podem ser usadas conjuntamente para revelar aspectos importantes de sistemas de transporte público descritos no formato GTFS.
Para informações sobre como checar a versão do Java instalado em seu computador e como instalar a versão correta, caso necessário, conferir o Capítulo 3.↩︎
Mensagens informativas podem também ser listadas no arquivo validation_stdout.txt. As mensagens listadas no validation_stderr.txt e no validation_stdout.txt dependem da versão do validador utilizada.↩︎